How Assistants work Beta
The Assistants API is designed to help developers build powerful AI assistants capable of performing a variety of tasks.
1. Assistants can call OpenAI’s **[models](/docs/models)** with specific instructions to tune their personality and capabilities.
2. Assistants can access **multiple tools in parallel**. These can be both OpenAI-hosted tools — like [code_interpreter](/docs/assistants/tools/code-interpreter) and [file_search](/docs/assistants/tools/file-search) — or tools you build / host (via [function calling](/docs/assistants/tools/function-calling)).
3. Assistants can access **persistent Threads**. Threads simplify AI application development by storing message history and truncating it when the conversation gets too long for the model’s context length. You create a Thread once, and simply append Messages to it as your users reply.
4. Assistants can access files in several formats — either as part of their creation or as part of Threads between Assistants and users. When using tools, Assistants can also create files (e.g., images, spreadsheets, etc) and cite files they reference in the Messages they create.
## Objects
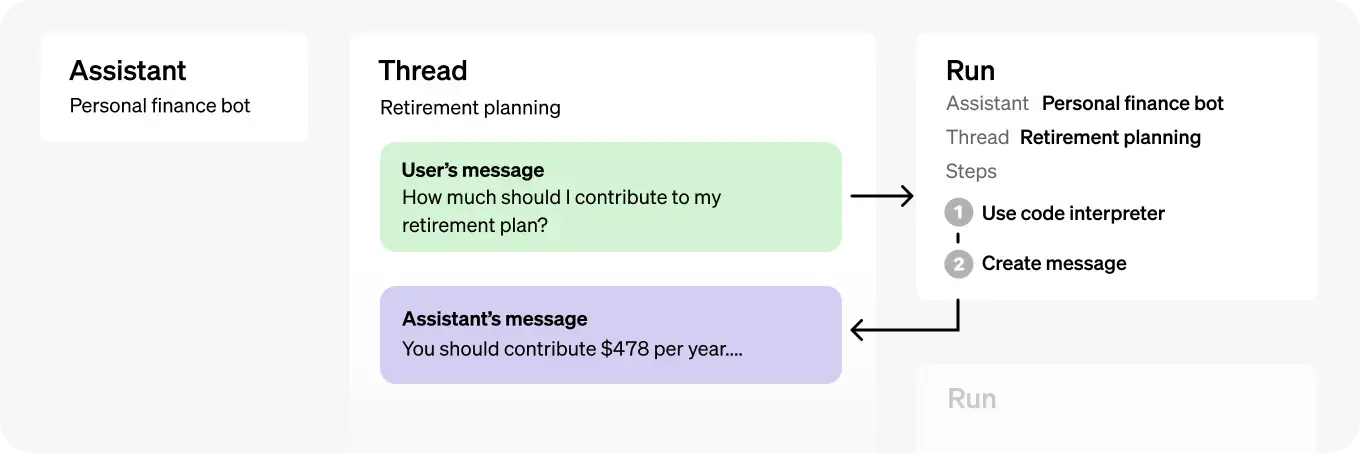
| Object | What it represents |
| --------- | ---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
| Assistant | Purpose-built AI that uses OpenAI’s [models](/docs/models) and calls [tools](/docs/assistants/tools) |
| Thread | A conversation session between an Assistant and a user. Threads store Messages and automatically handle truncation to fit content into a model’s context. |
| Message | A message created by an Assistant or a user. Messages can include text, images, and other files. Messages stored as a list on the Thread. |
| Run | An invocation of an Assistant on a Thread. The Assistant uses its configuration and the Thread’s Messages to perform tasks by calling models and tools. As part of a Run, the Assistant appends Messages to the Thread. |
| Run Step | A detailed list of steps the Assistant took as part of a Run. An Assistant can call tools or create Messages during its run. Examining Run Steps allows you to introspect how the Assistant is getting to its final results. |
## Creating Assistants
We recommend using OpenAI’s{" "}
latest models with the Assistants API
for best results and maximum compatibility with tools.
To get started, creating an Assistant only requires specifying the `model` to use. But you can further customize the behavior of the Assistant:
1. Use the `instructions` parameter to guide the personality of the Assistant and define its goals. Instructions are similar to system messages in the Chat Completions API.
2. Use the `tools` parameter to give the Assistant access to up to 128 tools. You can give it access to OpenAI-hosted tools like `code_interpreter` and `file_search`, or call a third-party tools via a `function` calling.
3. Use the `tool_resources` parameter to give the tools like `code_interpreter` and `file_search` access to files. Files are uploaded using the `File` [upload endpoint](/docs/api-reference/files/create) and must have the `purpose` set to `assistants` to be used with this API.
For example, to create an Assistant that can create data visualization based on a `.csv` file, first upload a file.
Then, create the Assistant with the `code_interpreter` tool enabled and provide the file as a resource to the tool.
You can attach a maximum of 20 files to `code_interpreter` and 10,000 files to `file_search` (using `vector_store` [objects](/docs/api-reference/vector-stores/object)).
Each file can be at most 512 MB in size and have a maximum of 5,000,000 tokens. By default, the size of all the files uploaded by your organization cannot exceed 100 GB, but you can reach out to our support team to increase this limit.
## Managing Threads and Messages
Threads and Messages represent a conversation session between an Assistant and a user. There is no limit to the number of Messages you can store in a Thread. Once the size of the Messages exceeds the context window of the model, the Thread will attempt to smartly truncate messages, before fully dropping the ones it considers the least important.
You can create a Thread with an initial list of Messages like this:
Messages can contain text, images, or file attachment. Message `attachments` are helper methods that add files to a thread's `tool_resources`. You can also choose to add files to the `thread.tool_resources` directly.
### Creating image input content
Message content can contain either external image URLs or File IDs uploaded via the [File API](/docs/api-reference/files/create). Only [models](/docs/models) with Vision support can accept image input. Supported image content types include png, jpg, gif, and webp. When creating image files, pass `purpose="vision"` to allow you to later download and display the input content. Currently, there is a 100GB limit per organization and 10GB for user in organization. Please contact us to request a limit increase.
Tools cannot access image content unless specified. To pass image files to Code Interpreter, add the file ID in the message `attachments` list to allow the tool to read and analyze the input. Image URLs cannot be downloaded in Code Interpreter today.
#### Low or high fidelity image understanding
By controlling the `detail` parameter, which has three options, `low`, `high`, or `auto`, you have control over how the model processes the image and generates its textual understanding.
- `low` will enable the "low res" mode. The model will receive a low-res 512px x 512px version of the image, and represent the image with a budget of 85 tokens. This allows the API to return faster responses and consume fewer input tokens for use cases that do not require high detail.
- `high` will enable "high res" mode, which first allows the model to see the low res image and then creates detailed crops of input images based on the input image size. Use the [pricing calculator](https://openai.com/api/pricing/) to see token counts for various image sizes.
### Context window management
The Assistants API automatically manages the truncation to ensure it stays within the model's maximum context length. You can customize this behavior by specifying the maximum tokens you'd like a run to utilize and/or the maximum number of recent messages you'd like to include in a run.
#### Max Completion and Max Prompt Tokens
To control the token usage in a single Run, set `max_prompt_tokens` and `max_completion_tokens` when creating the Run. These limits apply to the total number of tokens used in all completions throughout the Run's lifecycle.
For example, initiating a Run with `max_prompt_tokens` set to 500 and `max_completion_tokens` set to 1000 means the first completion will truncate the thread to 500 tokens and cap the output at 1000 tokens. If only 200 prompt tokens and 300 completion tokens are used in the first completion, the second completion will have available limits of 300 prompt tokens and 700 completion tokens.
If a completion reaches the `max_completion_tokens` limit, the Run will terminate with a status of `incomplete`, and details will be provided in the `incomplete_details` field of the Run object.
When using the File Search tool, we recommend setting the max_prompt_tokens to no less
than 20,000. For longer conversations or multiple interactions with File Search,
consider increasing this limit to 50,000, or ideally, removing the max_prompt_tokens
limits altogether to get the highest quality results.
#### Truncation Strategy
You may also specify a truncation strategy to control how your thread should be rendered into the model's context window.
Using a truncation strategy of type `auto` will use OpenAI's default truncation strategy. Using a truncation strategy of type `last_messages` will allow you to specify the number of the most recent messages to include in the context window.
### Message annotations
Messages created by Assistants may contain [`annotations`](/docs/api-reference/messages/object#messages/object-content) within the `content` array of the object. Annotations provide information around how you should annotate the text in the Message.
There are two types of Annotations:
1. `file_citation`: File citations are created by the [`file_search`](/docs/assistants/tools/file-search) tool and define references to a specific file that was uploaded and used by the Assistant to generate the response.
2. `file_path`: File path annotations are created by the [`code_interpreter`](/docs/assistants/tools/code-interpreter) tool and contain references to the files generated by the tool.
When annotations are present in the Message object, you'll see illegible model-generated substrings in the text that you should replace with the annotations. These strings may look something like `【13†source】` or `sandbox:/mnt/data/file.csv`. Here’s an example python code snippet that replaces these strings with information present in the annotations.
## Runs and Run Steps
When you have all the context you need from your user in the Thread, you can run the Thread with an Assistant of your choice.
By default, a Run will use the `model` and `tools` configuration specified in Assistant object, but you can override most of these when creating the Run for added flexibility:
Note: `tool_resources` associated with the Assistant cannot be overridden during Run creation. You must use the [modify Assistant](/docs/api-reference/assistants/modifyAssistant) endpoint to do this.
#### Run lifecycle
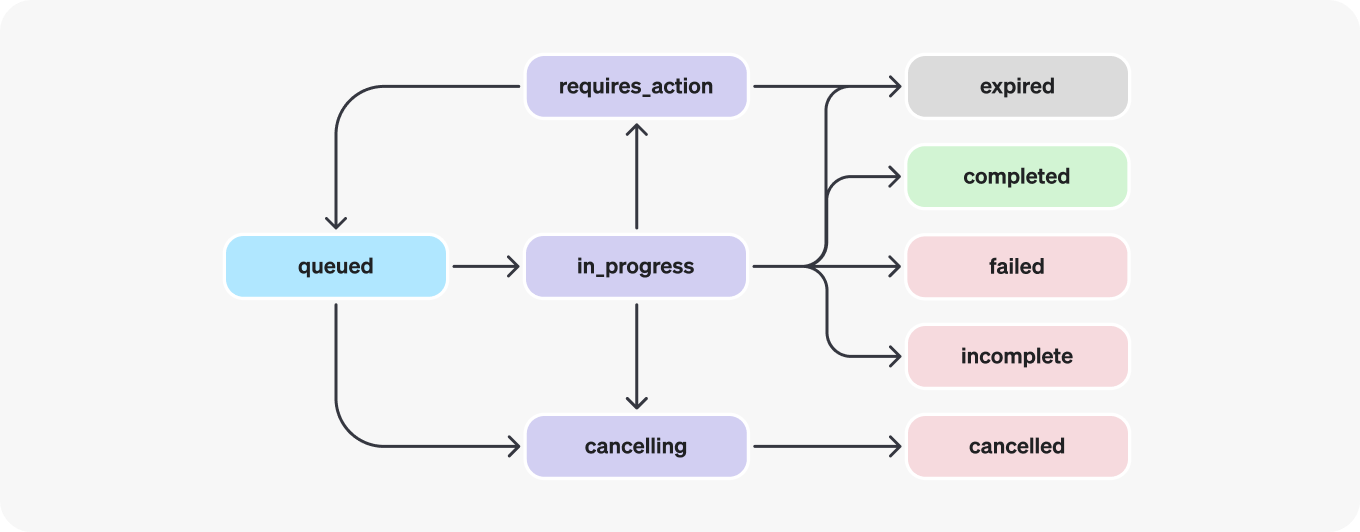
Run objects can have multiple statuses.
| Status | Definition |
| ----------------- | -------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
| `queued` | When Runs are first created or when you complete the `required_action`, they are moved to a queued status. They should almost immediately move to `in_progress`. |
| `in_progress` | While in_progress, the Assistant uses the model and tools to perform steps. You can view progress being made by the Run by examining the [Run Steps](/docs/api-reference/runs/step-object). |
| `completed` | The Run successfully completed! You can now view all Messages the Assistant added to the Thread, and all the steps the Run took. You can also continue the conversation by adding more user Messages to the Thread and creating another Run. |
| `requires_action` | When using the [Function calling](/docs/assistants/tools/function-calling) tool, the Run will move to a `required_action` state once the model determines the names and arguments of the functions to be called. You must then run those functions and [submit the outputs](/docs/api-reference/runs/submitToolOutputs) before the run proceeds. If the outputs are not provided before the `expires_at` timestamp passes (roughly 10 mins past creation), the run will move to an expired status. |
| `expired` | This happens when the function calling outputs were not submitted before `expires_at` and the run expires. Additionally, if the runs take too long to execute and go beyond the time stated in `expires_at`, our systems will expire the run. |
| `cancelling` | You can attempt to cancel an `in_progress` run using the [Cancel Run](/docs/api-reference/runs/cancelRun) endpoint. Once the attempt to cancel succeeds, status of the Run moves to `cancelled`. Cancellation is attempted but not guaranteed. |
| `cancelled` | Run was successfully cancelled. |
| `failed` | You can view the reason for the failure by looking at the `last_error` object in the Run. The timestamp for the failure will be recorded under `failed_at`. |
| `incomplete` | Run ended due to `max_prompt_tokens` or `max_completion_tokens` reached. You can view the specific reason by looking at the `incomplete_details` object in the Run. |
#### Polling for updates
If you are not using [streaming](/docs/assistants/overview/step-4-create-a-run?context=with-streaming), in order to keep the status of your run up to date, you will have to periodically [retrieve the Run](/docs/api-reference/runs/getRun) object. You can check the status of the run each time you retrieve the object to determine what your application should do next.
You can optionally use Polling Helpers in our [Node](https://github.com/openai/openai-node?tab=readme-ov-file#polling-helpers) and [Python](https://github.com/openai/openai-python?tab=readme-ov-file#polling-helpers) SDKs to help you with this. These helpers will automatically poll the Run object for you and return the Run object when it's in a terminal state.
#### Thread locks
When a Run is `in_progress` and not in a terminal state, the Thread is locked. This means that:
- New Messages cannot be added to the Thread.
- New Runs cannot be created on the Thread.
#### Run steps
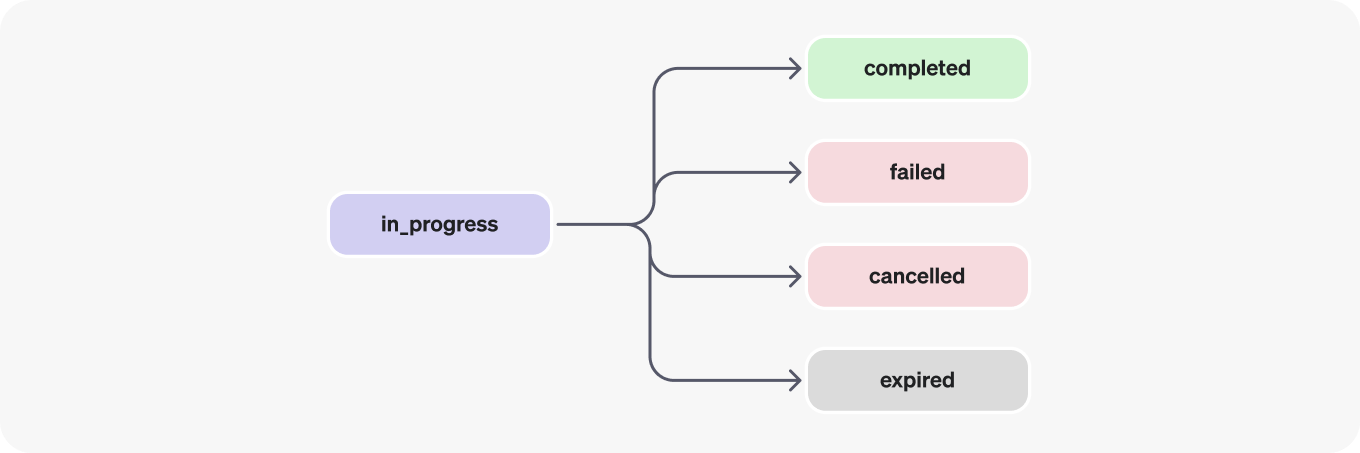
Run step statuses have the same meaning as Run statuses.
Most of the interesting detail in the Run Step object lives in the `step_details` field. There can be two types of step details:
1. `message_creation`: This Run Step is created when the Assistant creates a Message on the Thread.
2. `tool_calls`: This Run Step is created when the Assistant calls a tool. Details around this are covered in the relevant sections of the [Tools](/docs/assistants/tools) guide.
## Data access guidance
Currently, Assistants, Threads, Messages, and Vector Stores created via the API are scoped to the Project they're created in. As such, any person with API key access to that Project is able to read or write Assistants, Threads, Messages, and Runs in the Project.
We strongly recommend the following data access controls:
- _Implement authorization._ Before performing reads or writes on Assistants, Threads, Messages, and Vector Stores, ensure that the end-user is authorized to do so. For example, store in your database the object IDs that the end-user has access to, and check it before fetching the object ID with the API.
- _Restrict API key access._ Carefully consider who in your organization should have API keys and be part of a Project. Periodically audit this list. API keys enable a wide range of operations including reading and modifying sensitive information, such as Messages and Files.
- _Create separate accounts._ Consider creating separate Projects for different applications in order to isolate data across multiple applications.
## Next
Now that you have explored how Assistants work, the next step is to explore [Assistant Tools](/docs/assistants/tools) which covers topics like Function calling, File Search, and Code Interpreter.